Designing a keyboard from scratch - Part 1
Updates
- The decoupling capacitor section has been corrected to add a missing capacitor. There are 5 VCC pins on the Atmega32U4 and I was missing one.
- Thanks to Druz who discovered there was a mismatch between the reset button in the electronic schema and the footprint.
The article collection
This collection now contains the following articles:
- Part 1 (this one) - the electronic schema
- Part 2 - matrix & first steps of PCB layout
- Part 3 - routing the PCB
Preamble
I’ve been in the keyboard community for more than two years now and my keyboard collection is starting to fill up my shelves. It’s only recently that, as an engineer, I started to think about how keyboards were really working.
Some times ago, I got my hands on a 90s mint-condition Apple Extended Keyboard, some AEK keycaps and Alps SKCM switches. The idea I had, was to wait for a Group Buy to happen for an Alps based keyboard (like the ADK64) and then build a new keyboard with parts coming from old keyboards.
Alas, I missed all the nice Alps GB (ie the Lunar). Still I wanted to build a modern keyboard with those parts. One of the reasons is that I worked with such mechanical keyboards back in the 90s and I remember that their tactile feeling was among the best I’ve experienced.
So, an idea started to grow in my mind. What if I designed my own Alps based keyboard ? This way, I would be able to have the layout I want, instead of being forced in a 60% layout I’m not really fond of.
This series of articles will tell this adventure. My aim is to allow anyone to also start designing their own keyboards, piece by piece, but also understand how everything works.
At the time of writing, I have validated the PCB rev0, almost finished designing the case and plate, but the keyboard itself is yet not finished.
In this episode, we’ll focus on beginning the electronic schema (outside the matrix). The very next episode will focus on the matrix, assigning footprints, etc. Then we’ll have at least one episode on the PCB design.
The keyboard
So I said earlier that I got some Salmon and Orange Alps SKCM switches that were desoldered from an existing 90s AEK. The Salmon switches are not in a very good condition (they would require cleaning at least), but the orange ones are. I also have 2 sets of AEK keys, one in Japanese and the other one in ANSI layout (qwerty US).
The aim is to build a 65% ANSI keyboard with the following layout:

I codenamed this keyboard the AEK67 because there’s 67 keys in it, but I’m looking for a better name (any help would be very much appreciated on this front). You’ll notice that this layout is the same as the Lunar one. It also has the same issues:
- it requires a 1.75u RSHIFT in row 3
- it requires a 1u in row 4
The original AEK keyset doesn’t have those keys. There are possibilities of using a different key, for instance a Caps Lock, but it won’t have the right profile. The Lunar GB solved this issue by casting a specific 1.75u key in this profile, unfortunately I wasn’t able to get one. Well, we’ll see when the keyboard will be finished :)
Keyboard under the hood
Unlike my previous experiment at building a handwired keyboard, this time the aim is to design a full-fledged keyboard, including a PCB and a real case.
Since I needed to start somewhere, and I already had some basic electronics knowledge from my engineering degree (25 year ago), I started by designing the electronic board.
I explained a bit how a keyboard works in the handwired build log, but let’s refresh our memories. A keyboard is the combination of:
- keycaps (I’m covered)
- switches (that’s OK, I got them)
- a plate to secure the switches
- a PCB on which the switches are soldered
- a case
- optionally a weight
The PCB is the electronic board that converts key presses in commands that the computer can understand (that’s the HID protocol for USB). The PCB contains a micro controller (the MCU for short, it contains a CPU, a bit of RAM, flash memory and many I/O ports) and an array of switches (which form the matrix).
The switches are arranged in columns and rows to mimic the physical keys layout. At a very fast pace, the MCU will scan the matrix by providing a voltage on a given column, then the next one, etc and reading the lines.
If a key is depressed, the voltage will appear on the line of the pressed key when the MCU feeds the tension on its column, because the current will flow from the activated line to the row through the switch. The MCU deducts the key that has been depressed by looking at the rows and columns it is currently applying and reading the voltage.The MCU can then send the corresponding normalized key code on the USB wires to the computer (what the computer does is another story, sorry ;-)).
But there’s a problem: if one presses more than one key at a time, it is possible for the controller to register ghost keypresses. See the following schema of a conventional 4 switches matrix:
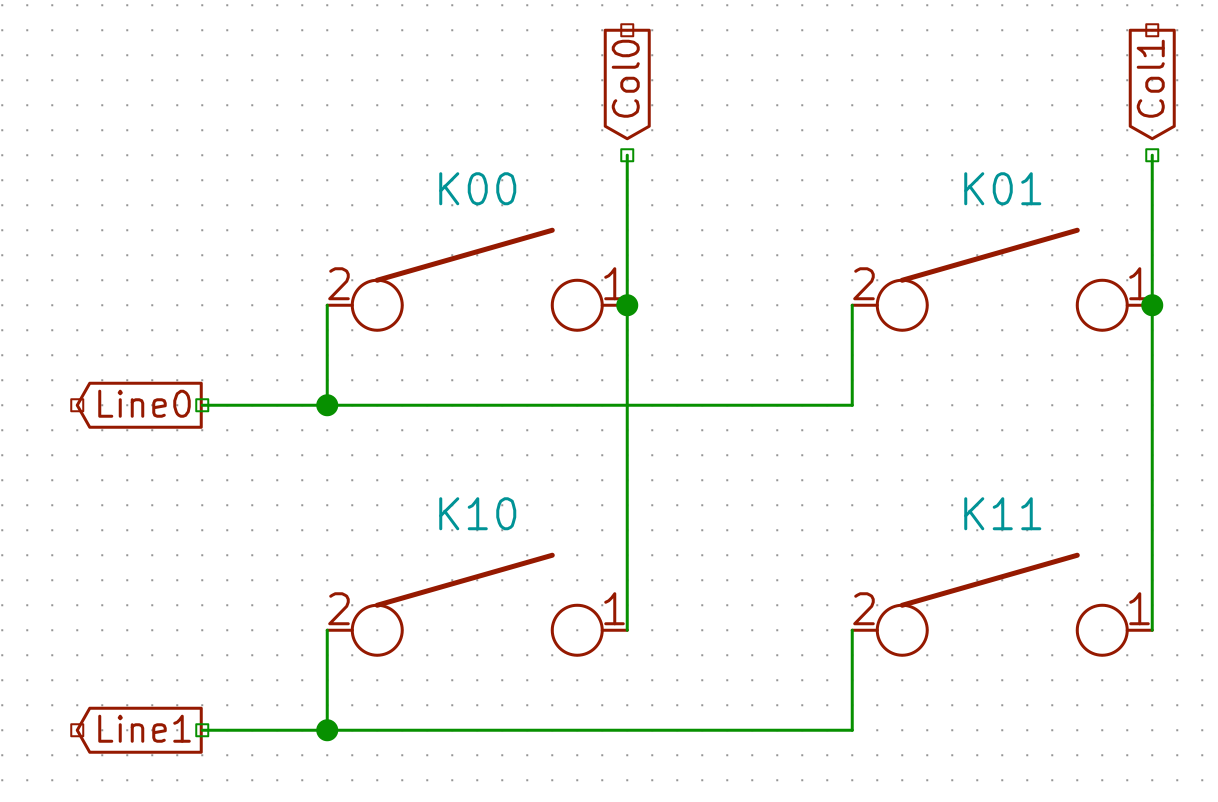
When the controller powers the Col0, and if K00, K01 and K11 are depressed simultaneously, the controller will see a tension on both Line0 and Line1, because the current will flow from Col0 to K00 pin 1, then pin 2 because the switch is closed, then to switch K01, then to switch K11, then to Line1. For the MCU it is as if all the switches have been pressed, instead of the 3 that were indeed depressed.
To prevent this we add diodes between the switch and the row it is connected to. Diodes are electronic components that prevent the current to flow in the reverse direction. The matrix becomes this:
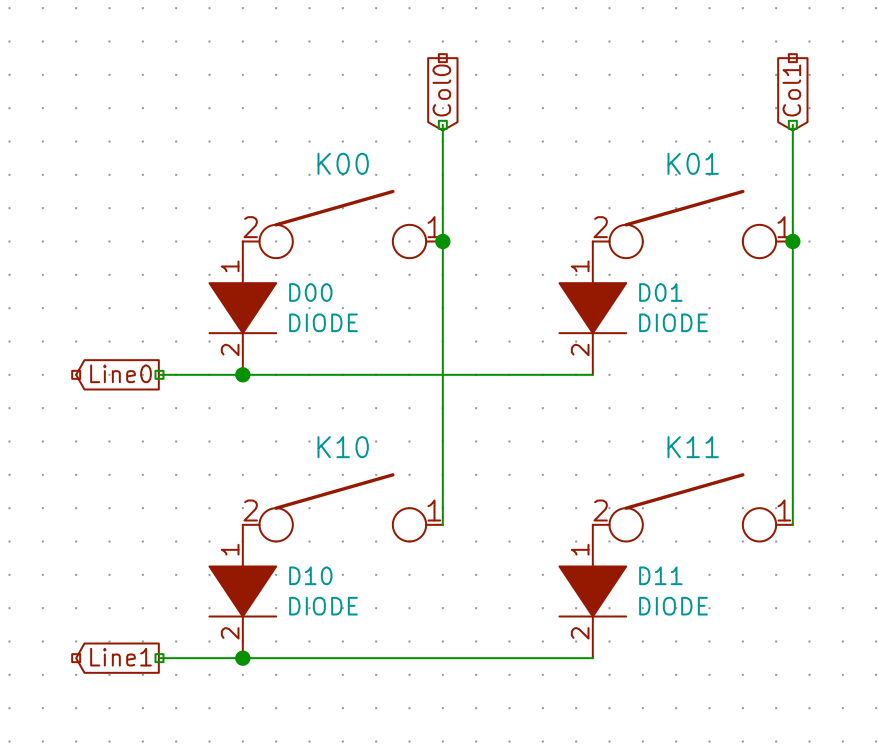
In the same hypothetical scenario as before, the current is prevented to flow back from K00 to K01 and from Line0 by the D01 diode. Thus when powering Col0, the controller will only see a tension on Line0, but not Line1. And when powering Col1 it will see a tension from Line0 and Line1, thus registering 3 key presses, as it should.
That being said, let’s start our work on the electronic schema.
Preparatory work
The last time I designed a PCB was during my engineering degree. And it was a long time ago. Things have changed nowadays. We now have open source software to design electronic schemas and PCB, no need to purchase a very expensive EDA software anymore, we have factories to build PCB at very low cost, etc.
Let’s start by installing the PCB design software: Kicad.
Since I was very rusty in this field, I needed a refresher on PCB design and keyboard inner workings. Hopefully, the keyboard community and especially ai03 has hosted a lot of very useful resources. The most important one is ai03’s awesome book on keyboard PCB design.
If you want to also start designing a PCB, I would suggest to read ai03’s tutorial (several times) and try to follow every steps. That’s a good way to get familiar with Kicad and its shortcuts.
One of his first advice is to work on the project under a git repository and to frequently commit. This is by far the most important advice I would recommend. It will allow you to come back in time if you fail something (and bonus point you can push to GitHub or any other central Git repository system to share your design).
So I started by creating a git repository, and added the keyboard kicad libraries I needed as git submodules:
- ai03’s MX & Alps switch footprint library. We’ll use it for the Alps switches footprints.
- ai03’s USB-C connector footprint library
- ai03’s random keyboard pars library, for the reset button
Once done, fire Kicad and choose “File” -> “New Project”, and locate your git repository (make sure to uncheck working in a subdirectory). Kicad will have created 2 files:
- the
.schfile containing the electric schema - the
.kicad_pcbfile containing the PCB itself
We’re going to add our symbols and footprint libraries to the Kicad project.
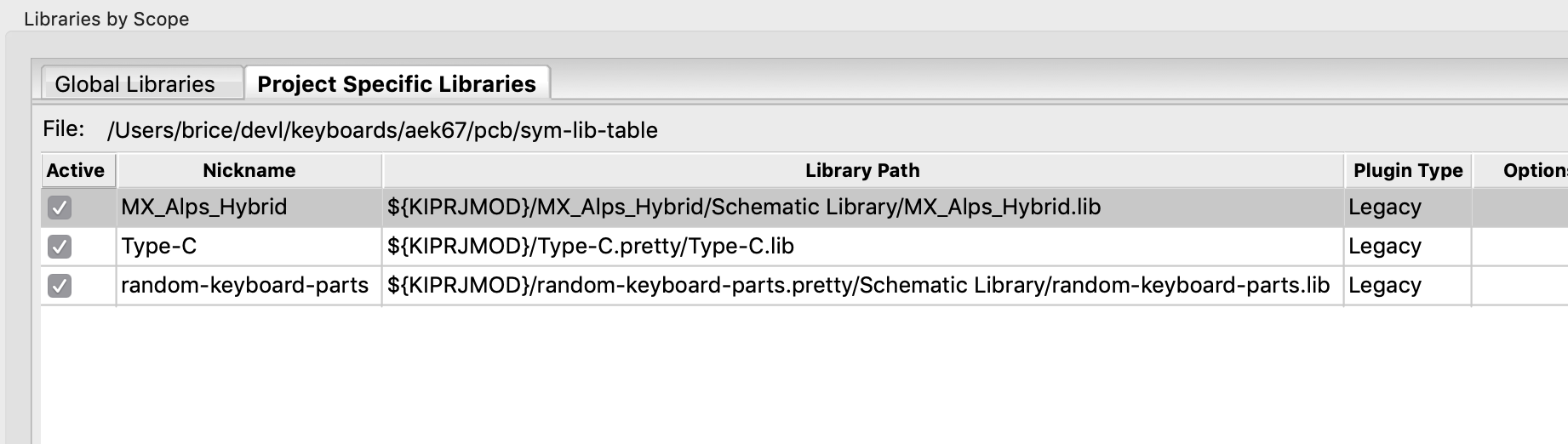
Go to Preferences -> Manage Symbol Libraries, then add our 3 libraries as explained in this screenshot:
Next, go to Preferences -> Manage Footprint Libraries, and add our 3 footprints libraries (do not pay attention to the 2 extras libraries in my screenshot as I took it in a different project):
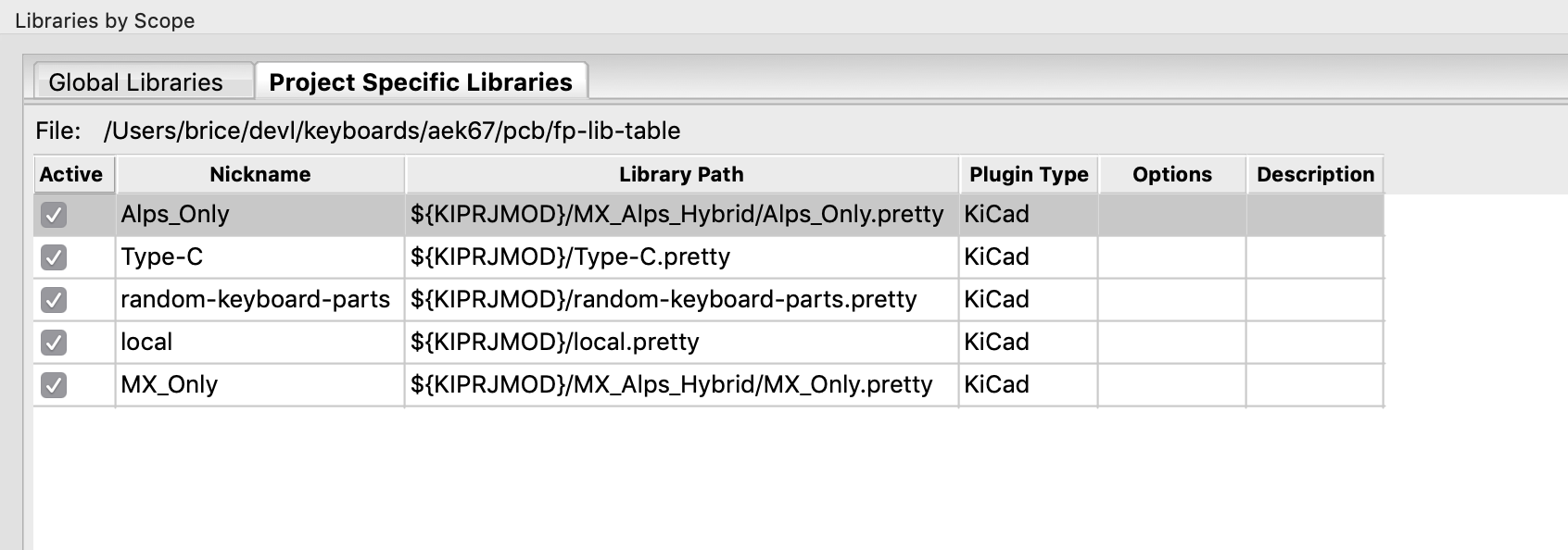
Note how I reference the libraries with the Kicad variable ${KIPRJMOD} which is a shorthand for the project location. This means that the project is relocatable (and anyone can check it out from GitHub without missing symbols problems).
Also note that I created a “local” footprints library in which we can put footprints we might need in this project but that are not in any specific library (or if we don’t want to import the whole library).
The electric schema
So the very first thing is to design the electric schema. In our case the electric schema has 3 distinct parts:
- the MCU and it’s wiring
- the USB port
- the switch matrix
We’re going to use an Atmega32U4 as the MCU. This is the iconic MCU for keyboards, it is inexpensive, very well supported by QMK, has direct USB connectivity, comes with a factory loaded boot-loader and has enough I/O to drive a 65% matrix.
The design will use an USB-C connector and a protection circuit to prevent electro-static discharges to destroy the keyboard electronics.
To start working on the electronic schema, we double click on the .sch file in the Kicad project. This opens a blank page in the eeschema application.
Follow ai03’s guide to setup the schema grid to 50mils or 25mils.
If you work with a trackpad, make sure to check all 3 checkboxes in the Preferences Zoom & Pan section, otherwise using Kicad becomes very counter intuitive.
To properly use the schema editor, you need to first add a given component (shortcut a) and then wire it accordingly to the data-sheet (shortcut w to draw wire, k to stop wire at the mouse position).
Any action can be cancelled by pressing the Esc key.
To copy an element use the shortcut c while the mouse pointer is on a component and move it (it will be very handy for switches). The shortcut g moves with the wire attached. And finally, you have to know the shortcut e to edit any component characteristic (this is very useful), r to rotate and y to flip a component.
I need to introduce here two notions:
- Labels: those are small text labels that you can attach to wires or pins to give them a name. All the wires that have the same labels are connected together without having to wire them physically in the schema.
- Power symbols: Kicad will automatically wire power symbols of the same name together on a power net. This is especially useful for the
GNDand+5Vsymbols, because those are virtually needed everywhere and we don’t want to clutter our schema with such wires.
To place a power symbol, just press p and open the ‘power’ submenu, scroll down to either +5V or GND, then click on the schema to place the symbol, use r to rotate it as you want.
By setting the grid to 50mils, the mouse pointer will snap from point grid to point grid. Every component will be laid out on this grid, and IC pins will also be aligned on such a grid. This way you make sure wires will be connected correctly to the pins of the component without having to precisely aim to the pins. If you were to use a smaller grid, you’d do a lot of small misalignment and some pins would end up not connected.
The MCU schema
The first thing to do is to add the Atmega32U4 symbol, by pressing the a key, then type Atmega32 in the component search window:
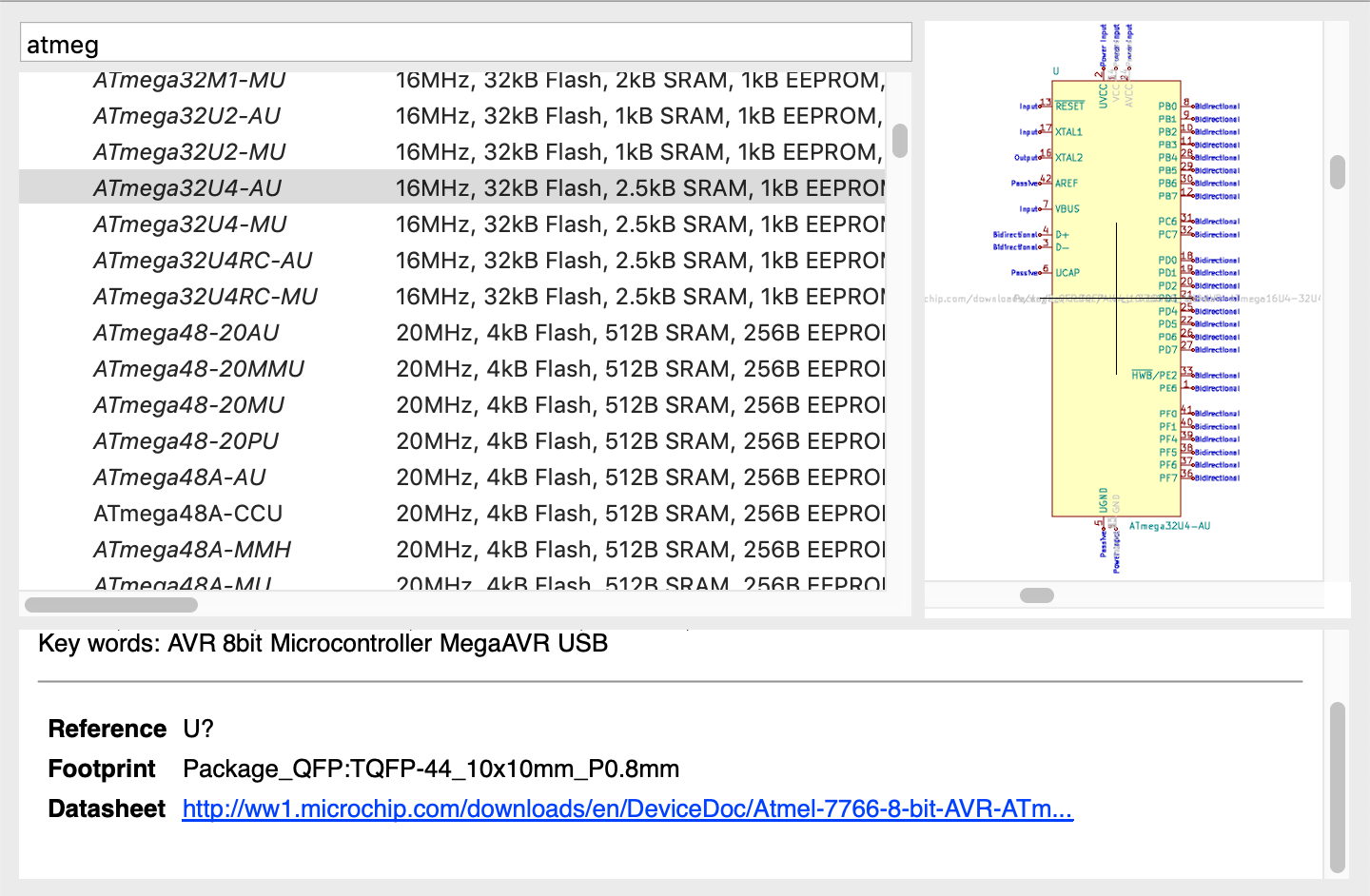
Let’s chose the official Kicad symbol for the Atmega32U4-AU. The AU package is a hand-solderable TQFP format (an IC with apparent pins, unlike the MU variant which is a QFN package where the pins are below making it difficult to solder with a standard solder iron).
Paste the MCU in the grid on the right part of the schema (but anywhere would work).
The MCU is easy to wire, and well explained in ai03’s guide, but to recap:
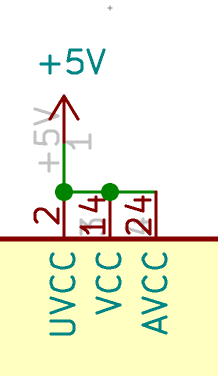
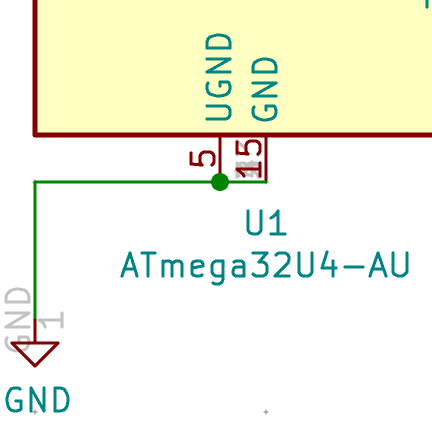
VCC,AVCC,UVCCshould be connected to the+5Vpower symbol.VBUSshould also be connected to the+5V.VBUSis used by the MCU to monitor if it is connected or disconnected to/from the USB port. The Atmega32U4 data-sheets requires it to connect to a 10µF capacitance (see below).GNDandUGNDshould be connected to theGNDpower symbol- most of the pins will be left unconnected for the moment, as they’ll be hooked to the matrix rows and columns later
This gives this:
The MCU can work without a clock, but it’s way better to provide it a real external clock. The external clock is a crystal oscillator (or resonator). It is a specific component that produces a square signal at 16 MHz (for our case, otherwise there are crystals for a lot of different frequencies). The MCU is using this clock to sequence instructions execution and other internal functions. When powered with +5V the Atmega32U4 can run at 16 MHz.
For the moment it is enough to add Global Labels to the pins. I’ll cover the crystal circuit a bit later:
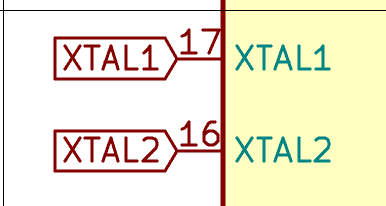
To add a label, press the Ctrl-H key and type it’s name (XTAL1), then place it onto the XTAL1 pin. Do the same with XTAL2. You might need to rotate the label either during creation or afterward (with r).
Let’s do the same with the D+/D- and RESET pins.
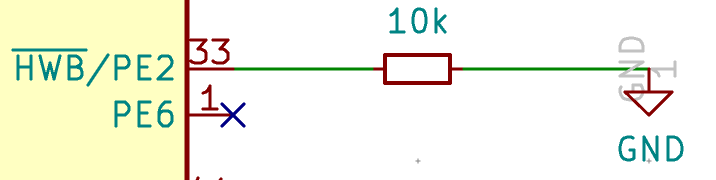
The next pin to wire is HWB. HWB is forced to GND with a pull down to make sure the MCU will boot with the boot-loader (refer to the data-sheet for more details). Create a R_small symbol for the resistor (we’ll use R_small symbols for all other resistors), then wire it like this:
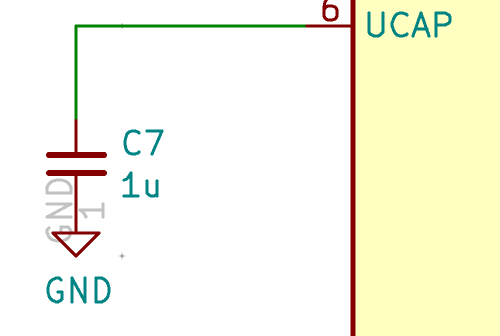
The UCAP is the internal USB pins voltage regulator, it has to be connected to a 1µF capacitor as instructed by the Atmega32U4 data-sheet. Use a C_small symbol for the capacitor (and all capacitors going forward)
AREF doesn’t need to be wired, we’re going to mark it with a cross by pressing q and clicking on the pin. AREF (and AVCC FWIW) is used when doing analog signaling which we’re not going to do in our keyboard.
Hooking the clock
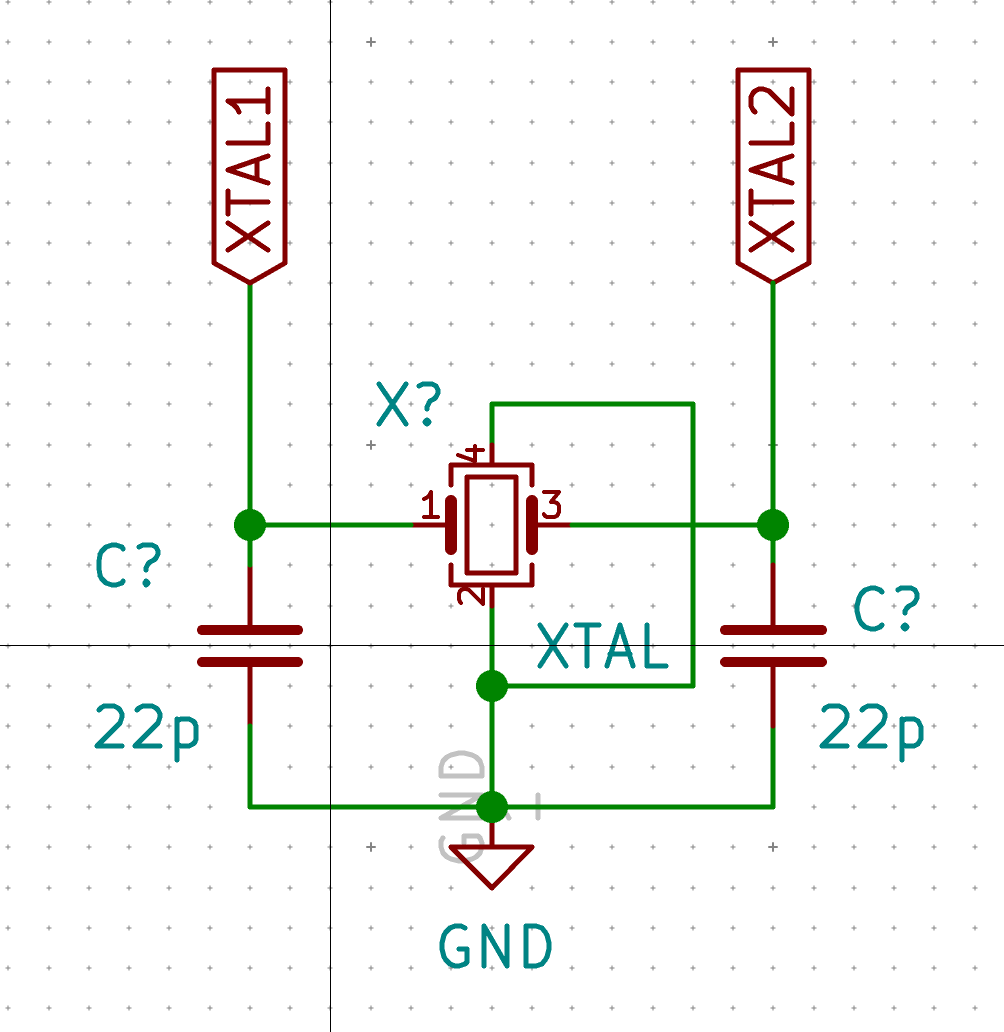
The very next step is to design the clock that drives the MCU and which will hook to the XTAL1 and XTAL2 labels.
The Atmega AN2519 tech-note gives a recommended design and equations to compute the capacitance values. Spoiler alert: the capacitor value is 22pF.
Place a Crystal_GND24_small on the grid close to the MCU. Then wire it like this:
Every component on Kicad has several properties. Among them, we find two important ones:
- the reference which is usually some letters followed by a number. It uniquely identifies a component on the schema
- the value can be anything. For passive components it is usually their values (in ohms for resistor, farads for capacitance, etc) or the component name for ICs.
The reference isn’t attributed when you add a new component to the schema, it contains one or more ?. There is an operation in Kicad that allows to automatically assign references to all the components (we’ll use it soon). This is necessary to be able to create a PCB or run the Electric Design Rule Checker, etc.
To edit the component values and reference, you can press e while hovering the mouse pointer on the symbol. This allows to edit all facets of a given component, including its reference, value, but also it’s symbol and footprint. There are shortcuts to edit the value (v) or the reference (u) directly.
It is possible to move the reference or value label of a component by pressing m while the mouse is over the component. It’s what I did in the crystal schema so that values and references are not colliding with any wires.
Power decoupling
The Atmega32U4 data-sheet recommends every +5V pins of the MCU to have decoupling capacitors. The decoupling capacitors play an important role for an active IC. If the component starts to draw current while doing its work, the voltage of the power source will drop, which could be problematic for the component itself but also for all other components powered by the same source (this creates noise on the power line).
To prevent this, we add decoupling capacitors on each power pin of the IC. Those decoupling capacitors will act as local energy storage. When the IC begins to consume energy the capacitors will be able to fulfill it without too much adverse effect on the power source. When the component doesn’t consume energy the decoupling capacitors refills gradually becoming ready for the next serve.
The AN2519 tech notes indicates that every VCC pins of the MCU should be decoupled by a 100nF (or 0.1µF) capacitor.
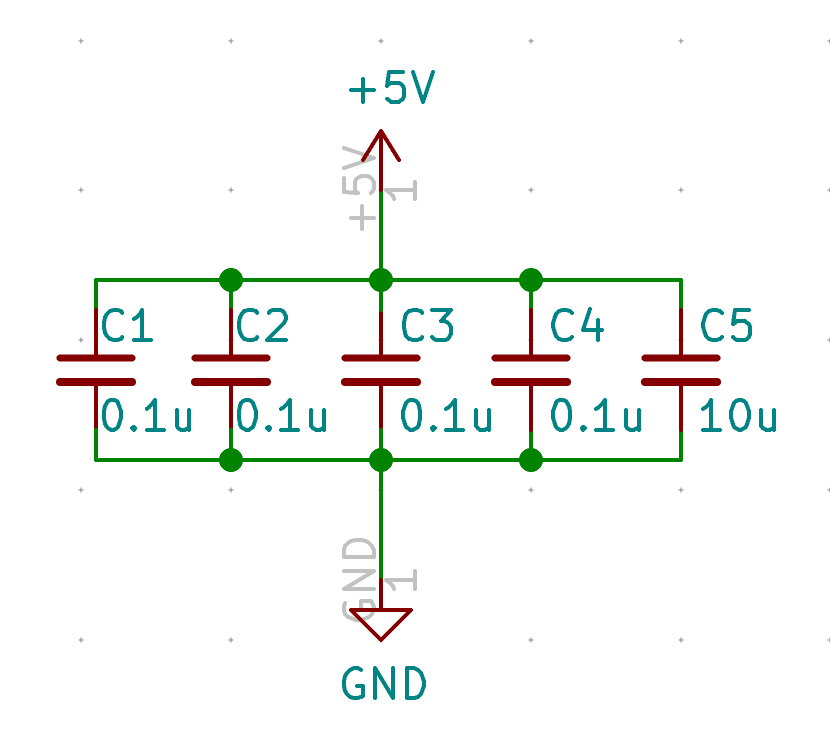
To be effective, the capacitor must be placed as close as possible from the MCU on the final PCB. Note that there are 4 VCC pins on the Atmega32U4 (2 AVCC, UVCC and 2 x VCC), so ideally we would need 5 100nF capacitor and one 10μF for VBUS. In practice, we can share the 10μF capacitor for both VBUS and UVCC and dispatch the 4 100nF to the other vcc pins.
To prevent cluttering the electronic schema, as ai03 suggests, I’ve placed those decoupling capacitors altogether in the schema.
Start by placing a capacitor, then use the c command to copy and move the next capacitor until you’ve placed all. Then wire them accordingly to this schema:
ISP header
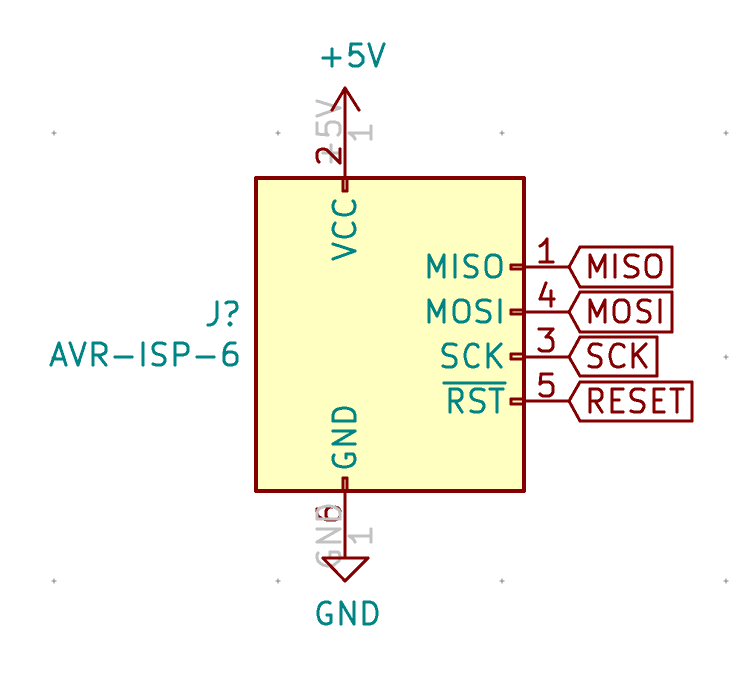
In case of catastrophic failure, it might be necessary to reprogram the Atmega32U4. In this case (for instance if we lost the DFU boot-loader), we can’t use the USB port to do that. We need to access the Serial Peripheral Interface (SPI) programming interface, and use the ISP programming mode.
To do this, we’re going to include on the PCB a 6 pins header with the SPI signals ready:
And associate it with the corresponding pins on the MCU:
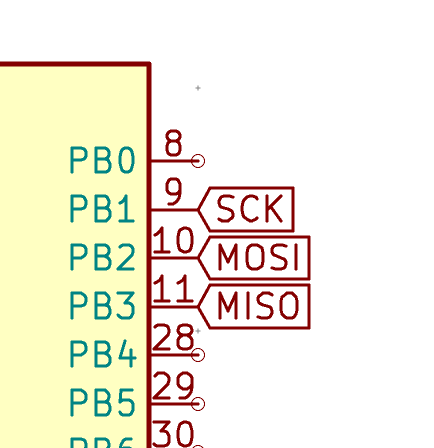
Notice that those 3 signals consume 3 general I/O pins which could be used for connecting the matrix. Since the matrix has 15 rows and 5 lines, it requires 20 I/O pins on the MCU. The MCU has thus enough available I/O pins. However if that wasn’t the case (for instance we might want to dedicate pins to RGB LEDs or backlighting or have a larger matrix), then it is very possible to share the ISP pins with the matrix. During ISP programming those matrix lines won’t be in use and during the keyboard use, the ISP pins won’t be in use. There are alternative matrix configurations to overcome a limited number of pins. Among them, you can double the number of rows and use the same “electrical” column for two consecutive physical columns. Another alternative is called Charlieplexing
Reset circuit
The keyboards needs to be flashed with a firmware (we’ll use the ubiquitous and opensource QMK).
The first time the Atmega32U4 boots, it will enter DFU mode because there’s no firmware loaded in the chip. The good thing with those MCU is that it is possible to flash them through the USB port and a program on the computer (for instance QMK Toolbox).
But, once done, if for any reason you need to update the firmware, there’s no way to make the firmware enter the DFU mode anymore (unless you included a RESET key combination in the keymap).
Hopefully, the MCU supports a way to perform an external reset, as the data-sheet explains: “The MCU is reset when a low level is present on the RESET pin for longer than the minimum pulse length.”
That means we can attach a push button to the reset pin to trigger a reset. But the tech notes also states: “The reset line has an internal pull-up resistor, but if the environment is noisy it can be insufficient and reset can therefore occur sporadically”. We don’t want to risk spurious reset, so we also need to add a pull-up resistor.
The AN2519 recommended design is the following one:
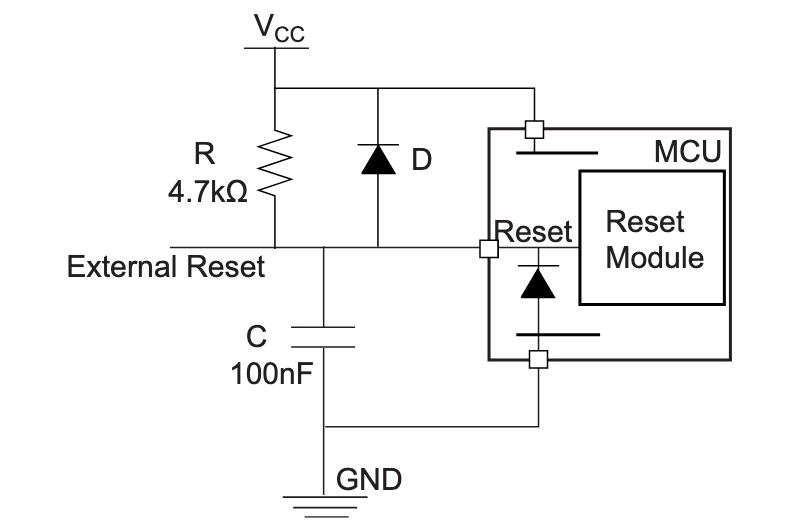
The tech-note recommended design adds a filtering capacitor to prevent noise in very noisy environments. I don’t think this keyboard will be used in such environments, we’re going to skip it (that’s one component less to solder, yay!).
The tech-note next paragraph adds the recommended design for a reset push button (this is to be combined with the):
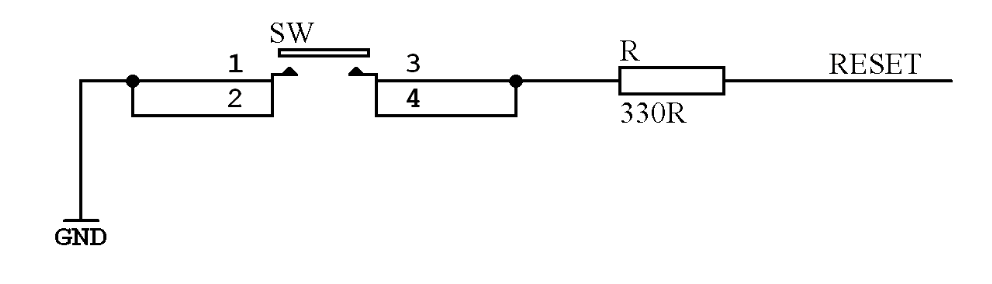
The 330 ohm resistor in series is to prevent a high current to form when shorting the capacitor at the moment the push button is pressed. This in turn would produce a high voltage on the RESET pin of the Atmega32u4 which could destroy it. Since we won’t use the capacitor, we don’t need this resistor altogether.
There’s no need to debounce the push button, because we really don’t care if we ever do multiple resets in a row when it is depressed.
There’s the question of the ESD protection diode parallel to the pull-up resistor. Since we don’t need His-Voltage/Parallel Programming (HVPP) for a keyboard (we’re going to do only USB and ISP flashing), the diode could be needed (otherwise it would prevent getting the 11V-15V needed on the RESET pin to trigger HVPP).
The ESD protection diode is just a standard diode (some recommend a Zener diode there). It protects from any electrostatic discharge damage. During the discharge, the external reset voltage is greater than 5.7V (Vcc 5V + 0.7V for the diode conduction), and the diode then conducts all the current toward the +5V source, thus protecting the RESET pin from the discharge current.
The diode has no interest for ESD protection if we only allow to reset with a push button (our case), but it might be of interest if we allow an external signal to trigger the reset. However the keyboard ISP header is for use only in case of emergency and will be hidden and protected in the keyboard case so the risk of ESD is quite negligible. I think it can be safe to remove this diode from the design.
Most open-source keyboard designs don’t have this diode either, probably for the same reason. To be noted that most of the Atmega32U4-based arduino board out-there don’t have the diode either.
For the real reset button I’m going to use a small SMD button like the RS-187R05A2-DS MT RT or the Alps SKQGAFE010.
The schematic of those buttons shows that there are 4 pins, each pair of pins connected horizontally. There’s no such symbol in Kicad yet. I could use a basic SW_PUSH with the alps footprint for instance and that would work fine. But I can also show you how to create your own symbol.
Let’s open the symbol editor from the Kicad main window. First I’ll create the local library (which has already been added to Kicad earlier). Then in this library, I’m creating the SW_SKQG symbol like this:
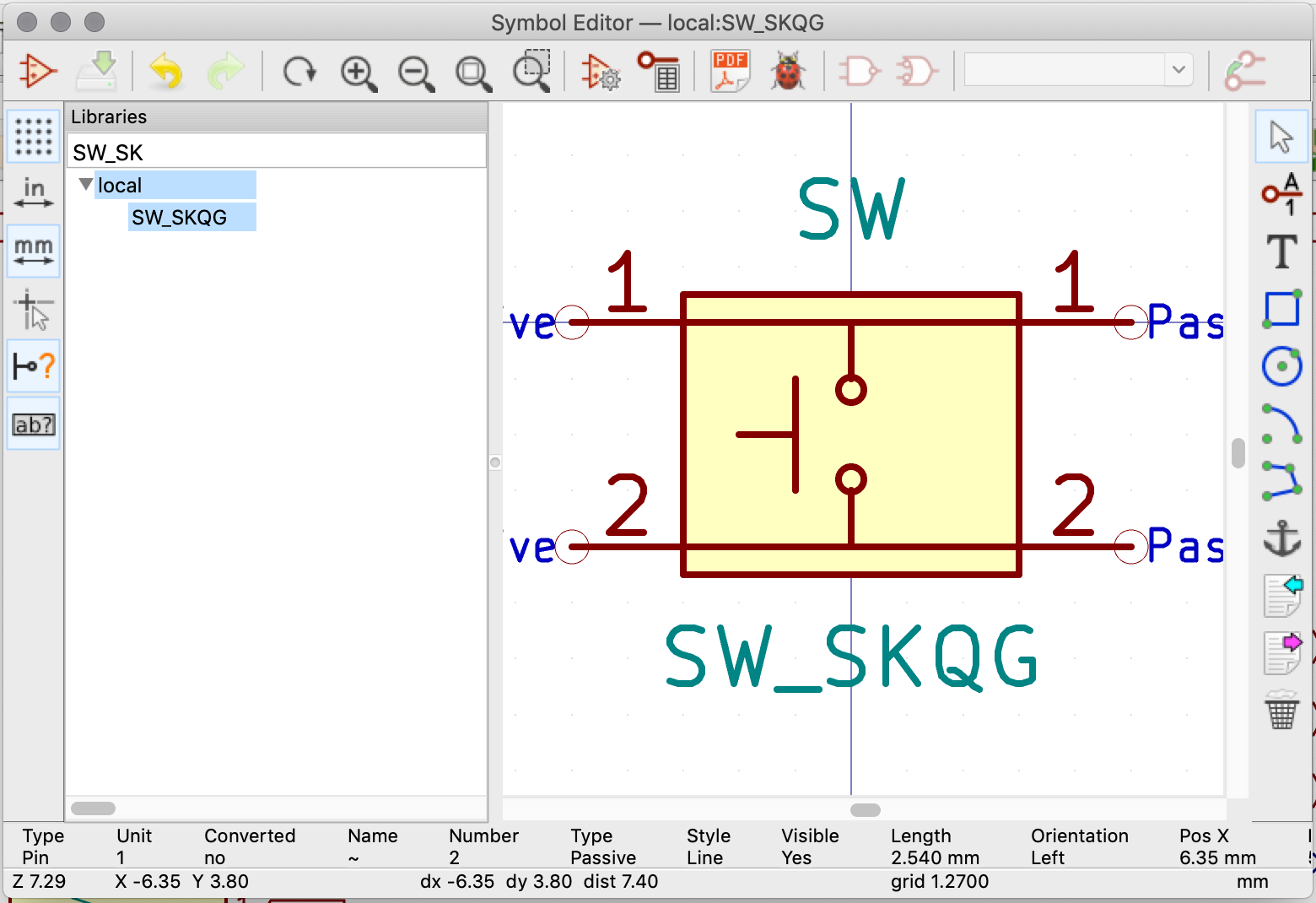
It’s composed of a rectangle, 4 pins labelled 1 & 2 and a few polylines and circles: nothing very complicated. Make sure to keep using the 50 mil grid settings to place the various pins, otherwise it will be difficult to connect the symbol in the schematic. Once done, save the symbol, it is ready to be used in the schematic:
So, finally my reset circuit looks like this:
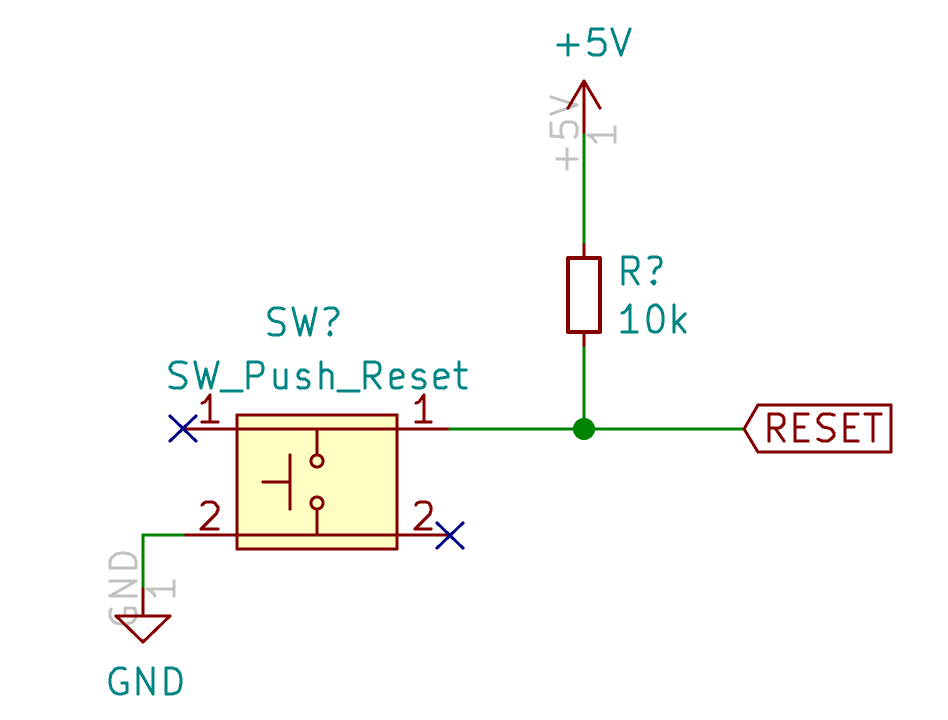
The USB connector
USB Type-C connector are much more usable than Type-B, because they can be reversed. The USB circuit needs to be as protective as possible for the rest of the keyboard electronics as I don’t want the electronic components to be destroyed by an electrostatic discharge (ESD). This means the circuit will have ESD protection on the data lines and power surge protection on the Vcc.
But for ease of building, the USB-C connector must be hand solderable. I had a good experience with the HRO Type-C-31-M-12. It is reasonably cheap, available and easy to hand-solder. Though, the shield contacts don’t completely go through a standard 1.6mm PCB (which is not an issue with metalized holes or thinner PCBs). It’s an USB 2.0 Type-C connector, perfect for a keyboard that doesn’t require hi-speed transfer.
So, let’s add a HRO-TYPE-C-31-M12 component to the schema. It is part of ai03’s Type-C library. An USB-C connector has 2x2 USB 2.0 signal wires, two D+ (DP1 and DP2) and two for D- (respectively DN1 and DN2). The reason there are 2 sets of lines is to provide the reversibility of the connector. We’ll start by connecting those together, with 22 ohms resistors as the Atmega32U4 data-sheet requires:
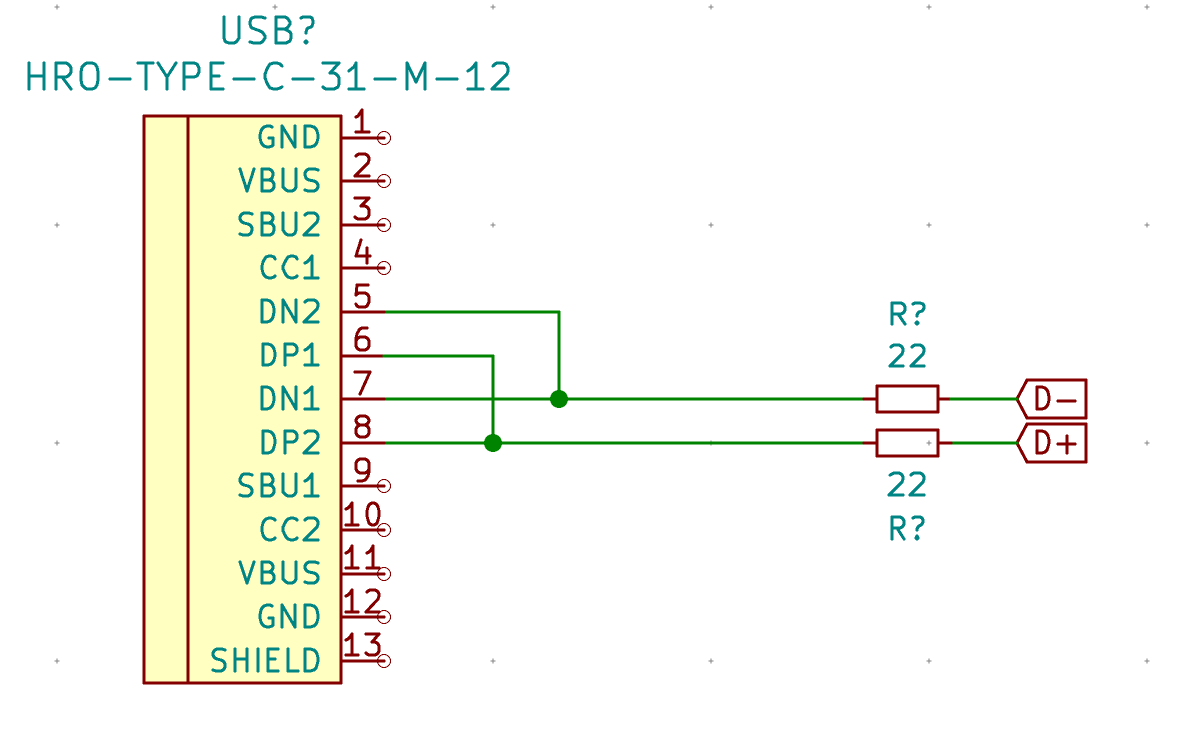
Next, wire both GND and the shield together, then both VBUS pins:
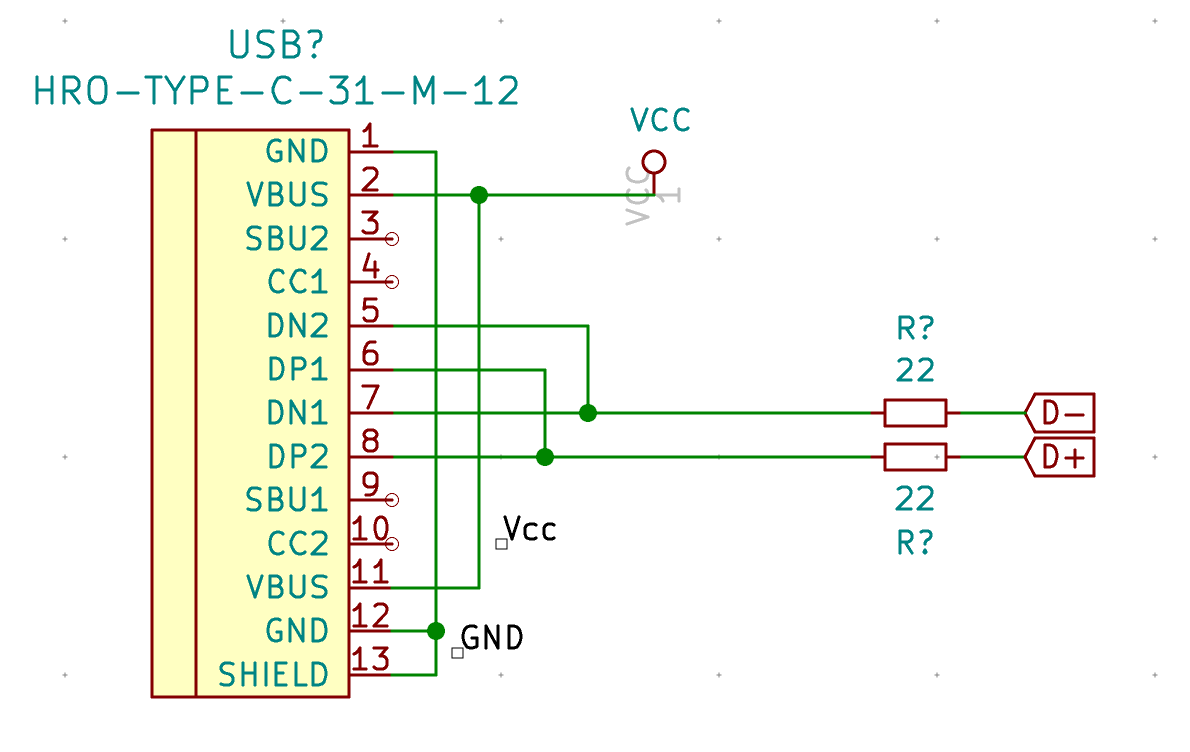
Note that we haven’t declared the +5V signal we’ve used elsewhere in the schema, instead we’ve declared Vcc. We’re going to add a fuse in the next step to protect our +5V against current surge.
Add a Polyfuse_Small to the schema connected to Vcc and +5V likes this:
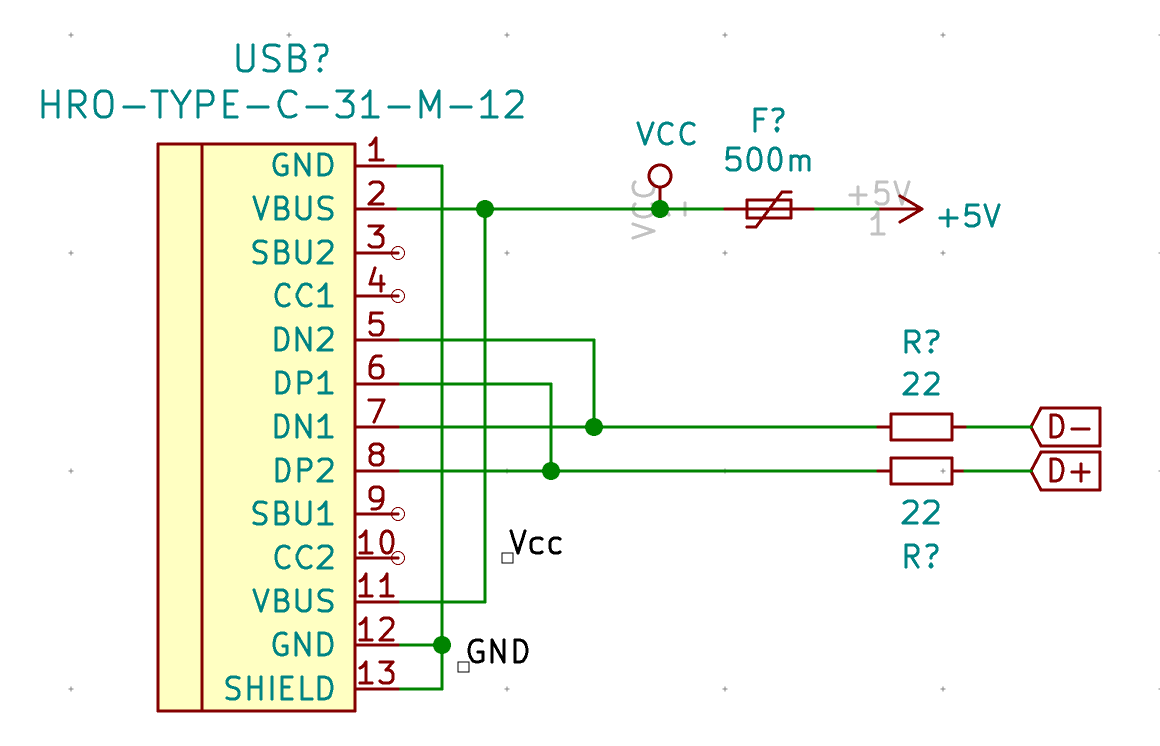
SBU1 and SBU2 are not used (it’s only for Alternate Mode like transporting HDMI or thunberbolt signals), so we can use the ‘No connect flag’ (Shift-Q) to place a black cross on those pins.
Next let’s focus a bit on the CC1 and CC2 pins. Those pins are the Channel Configuration pins. They are used to detect cable attachment and removal detection, plug orientation detection, etc.
The mechanism can be modeled like this:
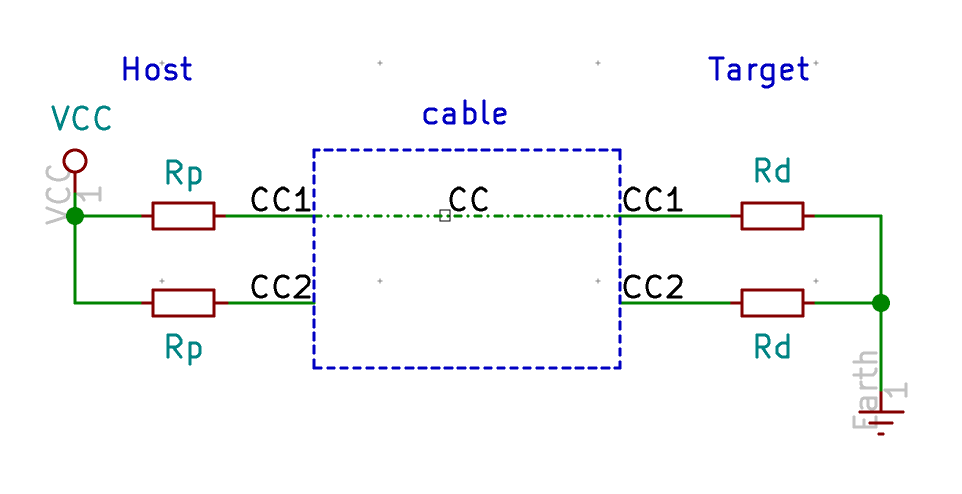
In the above schema we have the host (on the left) connected to the target (our keyboard on the right). Both equipments have pull-up (Rp) or pull-down (Rd) resistors. The USB-C cable has only one connector for CC. In the example above, the host will pull up the level of its CC1 and CC2 pins thanks to the pull-up resistor. The cable connects CC1 on the host to CC1 on the target, creating a current path from the +5V to GND. The host CC1 pin will then have a voltage of less than 5V, while CC2 will still has 5V (no charge). The host then knows the cable is connected (otherwise there would be 5V on both CC1 and CC2) and to which side it is connected to, magic!
Now if we flip the connector at the host for instance, we get the following schema:
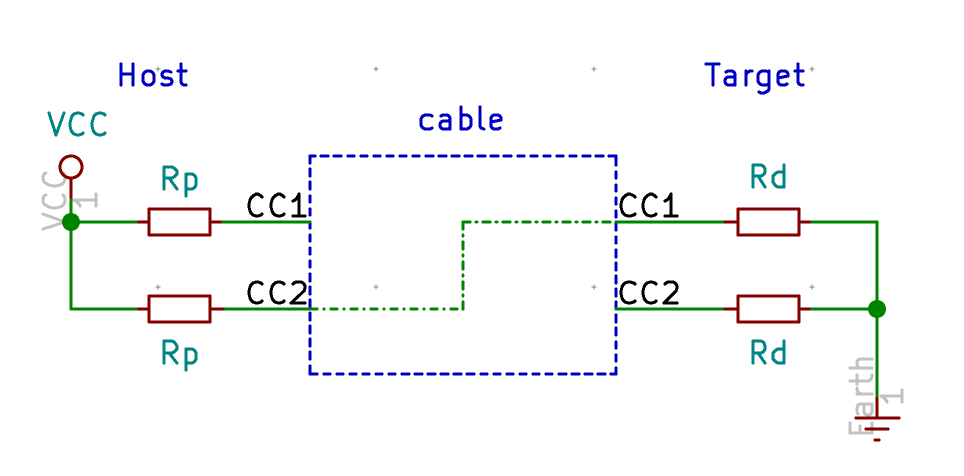
CC2 on the host will see less than 5V but CC1 will see 5V. The host detects it is connected through CC2 and not CC1 as in the previous example.
But there’s more. By choosing properly the value of the Rd resistors we can tell the host, as a target how much current we need to operate. For the USB standard 500mA (which is enough for powering our keyboard), we need 5.1k ohms resistors.
Let’s modify our schema now to add the CC pull-down resistors:
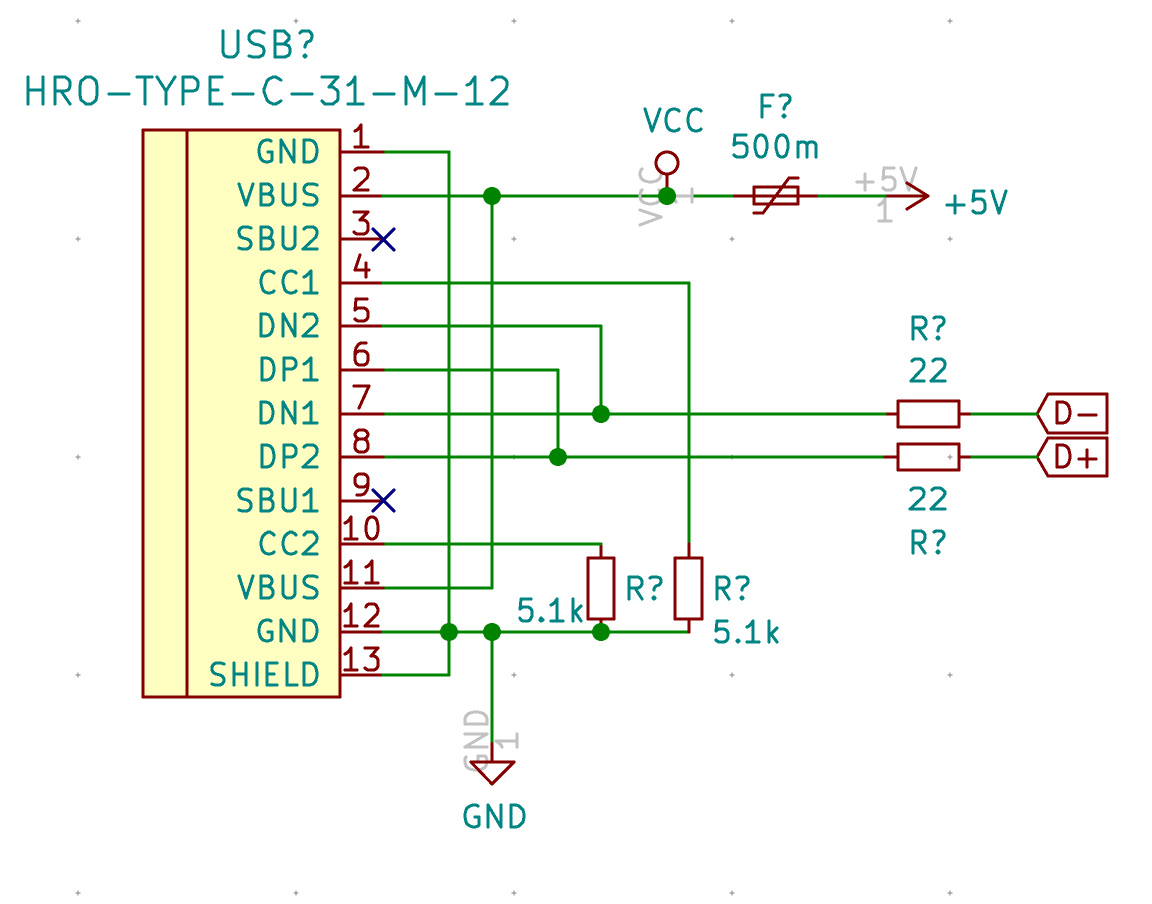
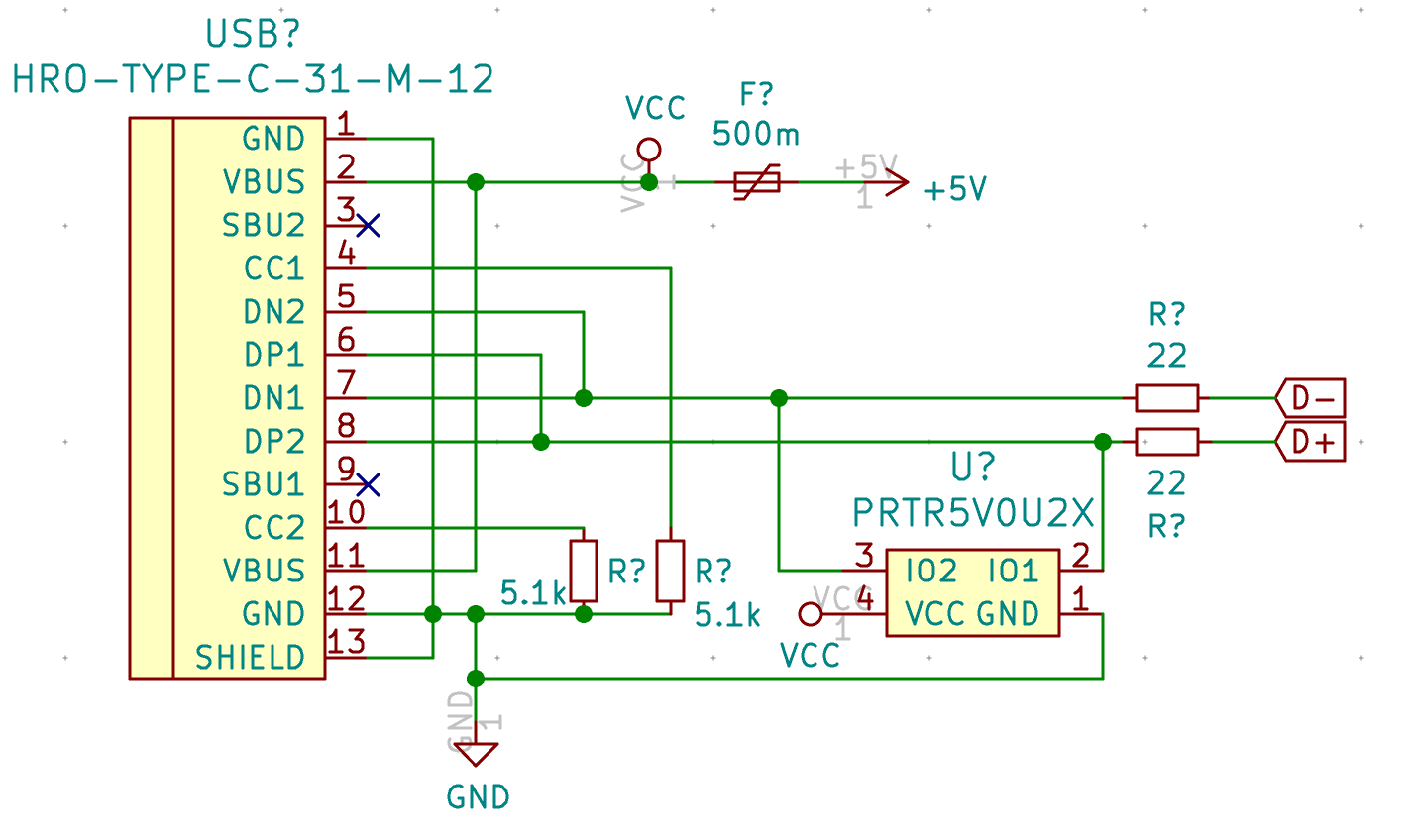
And finally we’re going to add the ESD protection system. We could use rail to rail discrete diodes, but it’s way easier to use an IC. There are several possibilities, one of the simplest is the PRTR5V0U2X. But you might find also the USBLC6 on some designs.
Here’s the modified schema with the PRTR5V0U2X connected to the data lines:
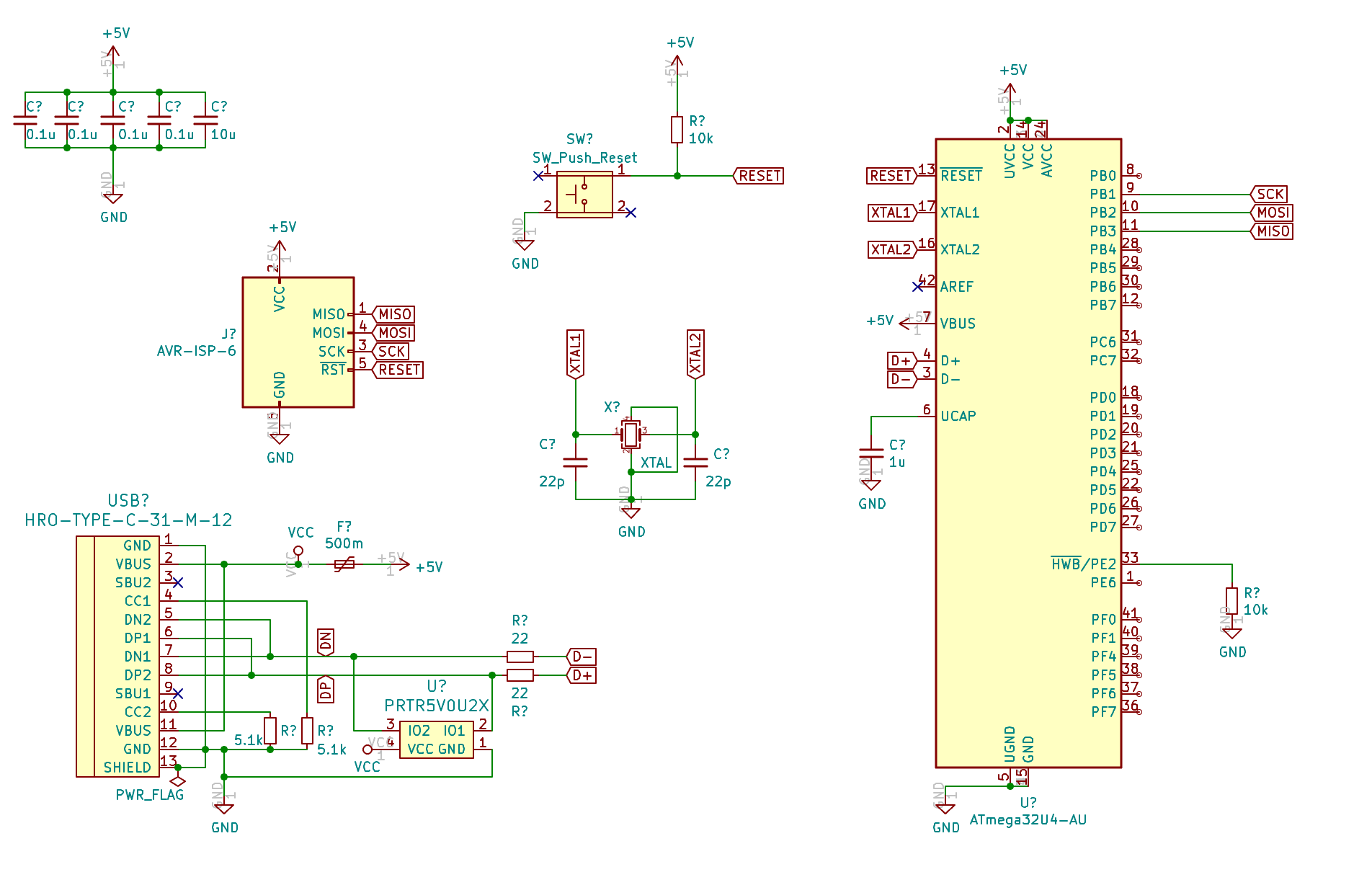
The big picture
If you followed the design so far, you should have the following schema:
What’s cooking next
We’re far from having a working PCB. I’m going to cover the following topics in the next episode:
- design the matrix
- reference the components
- check the EDC rules
- starts laying out the PCB
Then on the subsequent parts, I’ll cover soldering SMD components, configuring the firmware, testing the PCB, and designing the case.
Want to read the next part? Then click here for the Designing a Keyboard part 2































